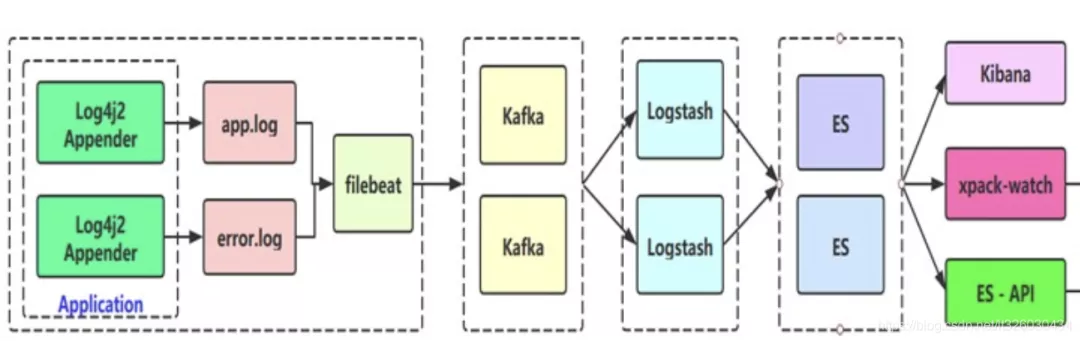
整体流程大概如下:
服务器准备
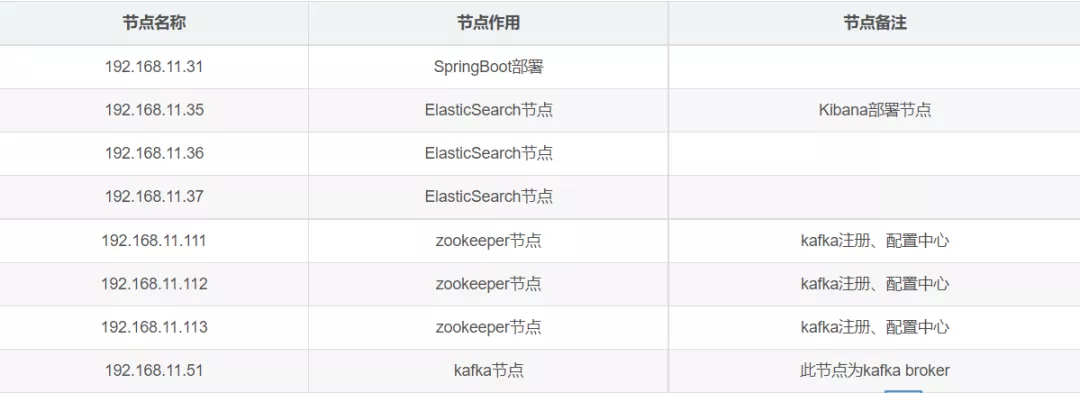
在这先列出各服务器节点,方便同学们在下文中对照节点查看相应内容
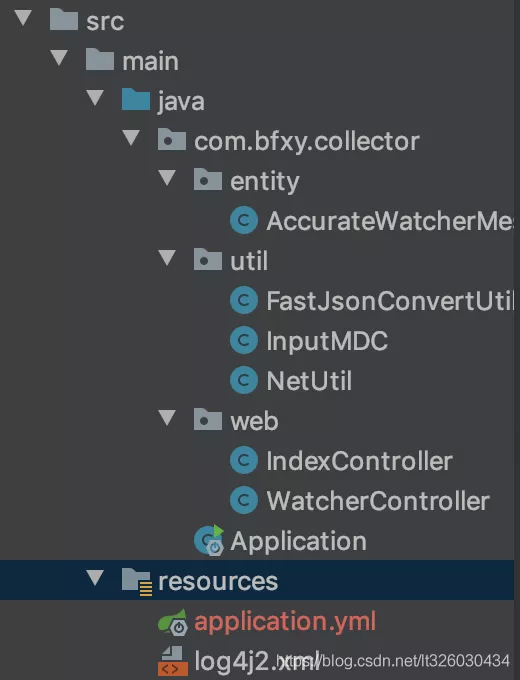
SpringBoot项目准备
引入log4j2替换SpringBoot默认log,demo项目结构如下:
pom
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| <dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.3.4</version>
</dependency>
</dependencies>
|
log4j2.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| <?xml version="1.0" encoding="UTF-8"?>
<Configuration status="INFO" schema="Log4J-V2.0.xsd" monitorInterval="600" >
<Properties>
<Property name="LOG_HOME">logs</Property>
<property name="FILE_NAME">collector</property>
<property name="patternLayout">[%d{yyyy-MM-dd'T'HH:mm:ss.SSSZZ}] [%level{length=5}] [%thread-%tid] [%logger] [%X{hostName}] [%X{ip}] [%X{applicationName}] [%F,%L,%C,%M] [%m] ## '%ex'%n</property>
</Properties>
<Appenders>
<Console name="CONSOLE" target="SYSTEM_OUT">
<PatternLayout pattern="${patternLayout}"/>
</Console>
<RollingRandomAccessFile name="appAppender" fileName="${LOG_HOME}/app-${FILE_NAME}.log" filePattern="${LOG_HOME}/app-${FILE_NAME}-%d{yyyy-MM-dd}-%i.log" >
<PatternLayout pattern="${patternLayout}" />
<Policies>
<TimeBasedTriggeringPolicy interval="1"/>
<SizeBasedTriggeringPolicy size="500MB"/>
</Policies>
<DefaultRolloverStrategy max="20"/>
</RollingRandomAccessFile>
<RollingRandomAccessFile name="errorAppender" fileName="${LOG_HOME}/error-${FILE_NAME}.log" filePattern="${LOG_HOME}/error-${FILE_NAME}-%d{yyyy-MM-dd}-%i.log" >
<PatternLayout pattern="${patternLayout}" />
<Filters>
<ThresholdFilter level="warn" onMatch="ACCEPT" onMismatch="DENY"/>
</Filters>
<Policies>
<TimeBasedTriggeringPolicy interval="1"/>
<SizeBasedTriggeringPolicy size="500MB"/>
</Policies>
<DefaultRolloverStrategy max="20"/>
</RollingRandomAccessFile>
</Appenders>
<Loggers>
<AsyncLogger name="com.bfxy.*" level="info" includeLocation="true">
<AppenderRef ref="appAppender"/>
</AsyncLogger>
<AsyncLogger name="com.bfxy.*" level="info" includeLocation="true">
<AppenderRef ref="errorAppender"/>
</AsyncLogger>
<Root level="info">
<Appender-Ref ref="CONSOLE"/>
<Appender-Ref ref="appAppender"/>
<AppenderRef ref="errorAppender"/>
</Root>
</Loggers>
</Configuration>
|
IndexController
测试Controller,用以打印日志进行调试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| @Slf4j
@RestController
public class IndexController {
@RequestMapping(value = "/index")
public String index() {
InputMDC.putMDC();
log.info("我是一条info日志");
log.warn("我是一条warn日志");
log.error("我是一条error日志");
return "idx";
}
@RequestMapping(value = "/err")
public String err() {
InputMDC.putMDC();
try {
int a = 1/0;
} catch (Exception e) {
log.error("算术异常", e);
}
return "err";
}
}
|
InputMDC
用以获取log中的[%X{hostName}]、[%X{ip}]、[%X{applicationName}]三个字段值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| @Component
public class InputMDC implements EnvironmentAware {
private static Environment environment;
@Override
public void setEnvironment(Environment environment) {
InputMDC.environment = environment;
}
public static void putMDC() {
MDC.put("hostName", NetUtil.getLocalHostName());
MDC.put("ip", NetUtil.getLocalIp());
MDC.put("applicationName", environment.getProperty("spring.application.name"));
}
}
|
NetUtil
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
| public class NetUtil {
public static String normalizeAddress(String address){
String[] blocks = address.split("[:]");
if(blocks.length > 2){
throw new IllegalArgumentException(address + " is invalid");
}
String host = blocks[0];
int port = 80;
if(blocks.length > 1){
port = Integer.valueOf(blocks[1]);
} else {
address += ":"+port;
}
String serverAddr = String.format("%s:%d", host, port);
return serverAddr;
}
public static String getLocalAddress(String address){
String[] blocks = address.split("[:]");
if(blocks.length != 2){
throw new IllegalArgumentException(address + " is invalid address");
}
String host = blocks[0];
int port = Integer.valueOf(blocks[1]);
if("0.0.0.0".equals(host)){
return String.format("%s:%d",NetUtil.getLocalIp(), port);
}
return address;
}
private static int matchedIndex(String ip, String[] prefix){
for(int i=0; i<prefix.length; i++){
String p = prefix[i];
if("*".equals(p)){
if(ip.startsWith("127.") ||
ip.startsWith("10.") ||
ip.startsWith("172.") ||
ip.startsWith("192.")){
continue;
}
return i;
} else {
if(ip.startsWith(p)){
return i;
}
}
}
return -1;
}
public static String getLocalIp(String ipPreference) {
if(ipPreference == null){
ipPreference = "*>10>172>192>127";
}
String[] prefix = ipPreference.split("[> ]+");
try {
Pattern pattern = Pattern.compile("[0-9]+\\.[0-9]+\\.[0-9]+\\.[0-9]+");
Enumeration<NetworkInterface> interfaces = NetworkInterface.getNetworkInterfaces();
String matchedIp = null;
int matchedIdx = -1;
while (interfaces.hasMoreElements()) {
NetworkInterface ni = interfaces.nextElement();
Enumeration<InetAddress> en = ni.getInetAddresses();
while (en.hasMoreElements()) {
InetAddress addr = en.nextElement();
String ip = addr.getHostAddress();
Matcher matcher = pattern.matcher(ip);
if (matcher.matches()) {
int idx = matchedIndex(ip, prefix);
if(idx == -1) continue;
if(matchedIdx == -1){
matchedIdx = idx;
matchedIp = ip;
} else {
if(matchedIdx>idx){
matchedIdx = idx;
matchedIp = ip;
}
}
}
}
}
if(matchedIp != null) return matchedIp;
return "127.0.0.1";
} catch (Exception e) {
return "127.0.0.1";
}
}
public static String getLocalIp() {
return getLocalIp("*>10>172>192>127");
}
public static String remoteAddress(SocketChannel channel){
SocketAddress addr = channel.socket().getRemoteSocketAddress();
String res = String.format("%s", addr);
return res;
}
public static String localAddress(SocketChannel channel){
SocketAddress addr = channel.socket().getLocalSocketAddress();
String res = String.format("%s", addr);
return addr==null? res: res.substring(1);
}
public static String getPid(){
RuntimeMXBean runtime = ManagementFactory.getRuntimeMXBean();
String name = runtime.getName();
int index = name.indexOf("@");
if (index != -1) {
return name.substring(0, index);
}
return null;
}
public static String getLocalHostName() {
try {
return (InetAddress.getLocalHost()).getHostName();
} catch (UnknownHostException uhe) {
String host = uhe.getMessage();
if (host != null) {
int colon = host.indexOf(':');
if (colon > 0) {
return host.substring(0, colon);
}
}
return "UnknownHost";
}
}
}
|
启动项目,访问/index和/ero接口,可以看到项目中生成了app-collector.log和error-collector.log两个日志文件

我们将Springboot服务部署在192.168.11.31这台机器上。
Kafka安装和启用
kafka下载地址:
http://kafka.apache.org/downloads.html
kafka安装步骤:首先kafka安装需要依赖与zookeeper,所以小伙伴们先准备好zookeeper环境(三个节点即可),然后我们来一起构建kafka broker。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| #
tar -zxvf kafka_2.12-2.1.0.tgz -C /usr/local/
#
mv kafka_2.12-2.1.0/ kafka_2.12
#
vim /usr/local/kafka_2.12/config/server.properties
#
broker.id=0
port=9092
host.name=192.168.11.51
advertised.host.name=192.168.11.51
log.dirs=/usr/local/kafka_2.12/kafka-logs
num.partitions=2
zookeeper.connect=192.168.11.111:2181,192.168.11.112:2181,192.168.11.113:2181
#
mkdir /usr/local/kafka_2.12/kafka-logs
#
/usr/local/kafka_2.12/bin/kafka-server-start.sh /usr/local/kafka_2.12/config/server.properties &
|
创建两个topic
1
2
3
| #
kafka-topics.sh --zookeeper 192.168.11.111:2181 --create --topic app-log-collector --partitions 1 --replication-factor 1
kafka-topics.sh --zookeeper 192.168.11.111:2181 --create --topic error-log-collector --partitions 1 --replication-factor 1
|
我们可以查看一下topic情况
1
| kafka-topics.sh --zookeeper 192.168.11.111:2181 --topic app-log-test --describe
|
可以看到已经成功启用了app-log-collector和error-log-collector两个topic

filebeat安装和启用
filebeat下载
1
2
3
4
| cd /usr/local/software
tar -zxvf filebeat-6.6.0-linux-x86_64.tar.gz -C /usr/local/
cd /usr/local
mv filebeat-6.6.0-linux-x86_64/ filebeat-6.6.0
|
配置filebeat,可以参考下方yml配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| vim /usr/local/filebeat-5.6.2/filebeat.yml
#
filebeat.prospectors:
- input_type: log
paths:
## app-服务名称.log, 为什么写死,防止发生轮转抓取历史数据
- /usr/local/logs/app-collector.log
#定义写入 ES 时的 _type 值
document_type: "app-log"
multiline:
#pattern: '^\s*(\d{4}|\d{2})\-(\d{2}|[a-zA-Z]{3})\-(\d{2}|\d{4})' # 指定匹配的表达式(匹配以 2017-11-15 08:04:23:889 时间格式开头的字符串)
pattern: '^\[' # 指定匹配的表达式(匹配以 "{ 开头的字符串)
negate: true # 是否匹配到
match: after # 合并到上一行的末尾
max_lines: 2000 # 最大的行数
timeout: 2s # 如果在规定时间没有新的日志事件就不等待后面的日志
fields:
logbiz: collector
logtopic: app-log-collector ## 按服务划分用作kafka topic
evn: dev
- input_type: log
paths:
- /usr/local/logs/error-collector.log
document_type: "error-log"
multiline:
#pattern: '^\s*(\d{4}|\d{2})\-(\d{2}|[a-zA-Z]{3})\-(\d{2}|\d{4})' # 指定匹配的表达式(匹配以 2017-11-15 08:04:23:889 时间格式开头的字符串)
pattern: '^\[' # 指定匹配的表达式(匹配以 "{ 开头的字符串)
negate: true # 是否匹配到
match: after # 合并到上一行的末尾
max_lines: 2000 # 最大的行数
timeout: 2s # 如果在规定时间没有新的日志事件就不等待后面的日志
fields:
logbiz: collector
logtopic: error-log-collector ## 按服务划分用作kafka topic
evn: dev
output.kafka:
enabled: true
hosts: ["192.168.11.51:9092"]
topic: '%{[fields.logtopic]}'
partition.hash:
reachable_only: true
compression: gzip
max_message_bytes: 1000000
required_acks: 1
logging.to_files: true
|
filebeat启动:
检查配置是否正确
1
2
3
| cd /usr/local/filebeat-6.6.0
./filebeat -c filebeat.yml -configtest
#
|
启动filebeat
1
| /usr/local/filebeat-6.6.0/filebeat &
|
检查是否启动成功
可以看到filebeat已经启动成功

然后我们访问192.168.11.31:8001/index和192.168.11.31:8001/err,再查看kafka的logs文件,可以看到已经生成了app-log-collector-0和error-log-collector-0文件,说明filebeat已经帮我们把数据收集好放到了kafka上。
logstash安装
我们在logstash的安装目录下新建一个文件夹
然后cd进该文件,创建一个logstash-script.conf文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
| cd scrpit
vim logstash-script.conf
#
input {
kafka {
## app-log-服务名称
topics_pattern => "app-log-.*"
bootstrap_servers => "192.168.11.51:9092"
codec => json
consumer_threads => 1 ## 增加consumer的并行消费线程数
decorate_events => true
#auto_offset_rest => "latest"
group_id => "app-log-group"
}
kafka {
## error-log-服务名称
topics_pattern => "error-log-.*"
bootstrap_servers => "192.168.11.51:9092"
codec => json
consumer_threads => 1
decorate_events => true
#auto_offset_rest => "latest"
group_id => "error-log-group"
}
}
filter {
#
ruby {
code => "event.set('index_time',event.timestamp.time.localtime.strftime('%Y.%m.%d'))"
}
if "app-log" in [fields][logtopic]{
grok {
## 表达式,这里对应的是Springboot输出的日志格式
match => ["message", "\[%{NOTSPACE:currentDateTime}\] \[%{NOTSPACE:level}\] \[%{NOTSPACE:thread-id}\] \[%{NOTSPACE:class}\] \[%{DATA:hostName}\] \[%{DATA:ip}\] \[%{DATA:applicationName}\] \[%{DATA:location}\] \[%{DATA:messageInfo}\] ## (\'\'|%{QUOTEDSTRING:throwable})"]
}
}
if "error-log" in [fields][logtopic]{
grok {
## 表达式
match => ["message", "\[%{NOTSPACE:currentDateTime}\] \[%{NOTSPACE:level}\] \[%{NOTSPACE:thread-id}\] \[%{NOTSPACE:class}\] \[%{DATA:hostName}\] \[%{DATA:ip}\] \[%{DATA:applicationName}\] \[%{DATA:location}\] \[%{DATA:messageInfo}\] ## (\'\'|%{QUOTEDSTRING:throwable})"]
}
}
}
#
output {
stdout { codec => rubydebug }
}
#
output {
if "app-log" in [fields][logtopic]{
#
elasticsearch {
# es服务地址
hosts => ["192.168.11.35:9200"]
# 用户名密码
user => "elastic"
password => "123456"
## 索引名,+ 号开头的,就会自动认为后面是时间格式:
## javalog-app-service-2019.01.23
index => "app-log-%{[fields][logbiz]}-%{index_time}"
# 是否嗅探集群ip:一般设置true;http://192.168.11.35:9200/_nodes/http?pretty
# 通过嗅探机制进行es集群负载均衡发日志消息
sniffing => true
# logstash默认自带一个mapping模板,进行模板覆盖
template_overwrite => true
}
}
if "error-log" in [fields][logtopic]{
elasticsearch {
hosts => ["192.168.11.35:9200"]
user => "elastic"
password => "123456"
index => "error-log-%{[fields][logbiz]}-%{index_time}"
sniffing => true
template_overwrite => true
}
}
}
|
启动logstash
1
| /usr/local/logstash-6.6.0/bin/logstash -f /usr/local/logstash-6.6.0/script/logstash-script.conf &
|
等待启动成功,我们再次访问192.168.11.31:8001/err
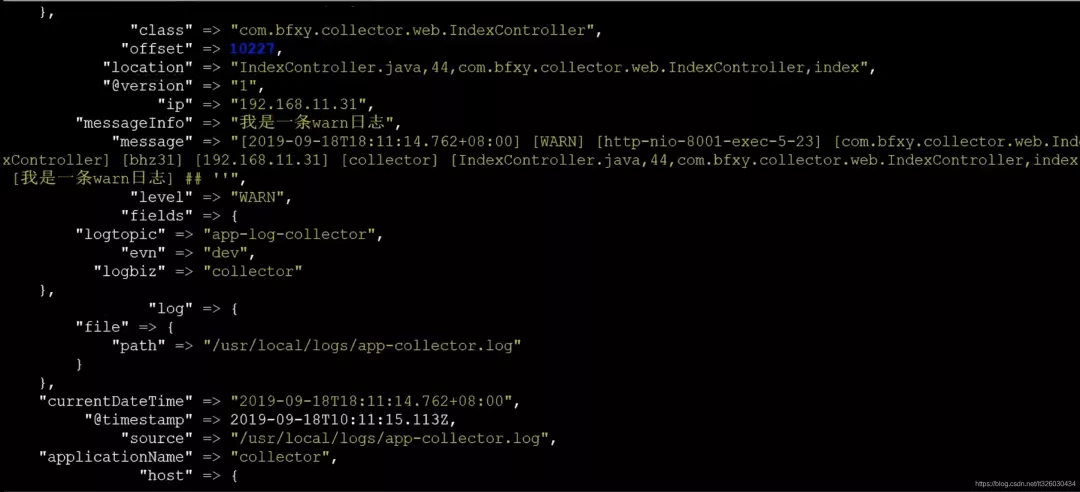
可以看到控制台开始打印日志
ElasticSearch与Kibana

ES和Kibana的搭建之前没写过博客,网上资料也比较多,大家可以自行搜索。
搭建完成后,访问Kibana的管理页面192.168.11.35:5601,选择Management -> Kinaba - Index Patterns
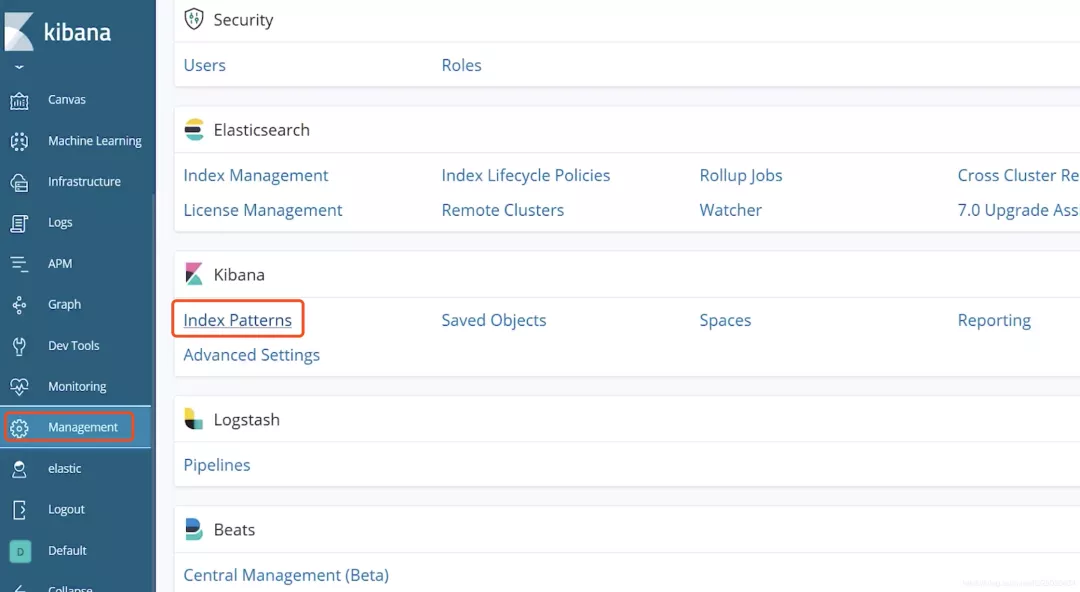
然后Create index pattern
- index pattern 输入
app-log-*
- Time Filter field name 选择 currentDateTime
这样我们就成功创建了索引。
我们再次访问192.168.11.31:8001/err,这个时候就可以看到我们已经命中了一条log信息
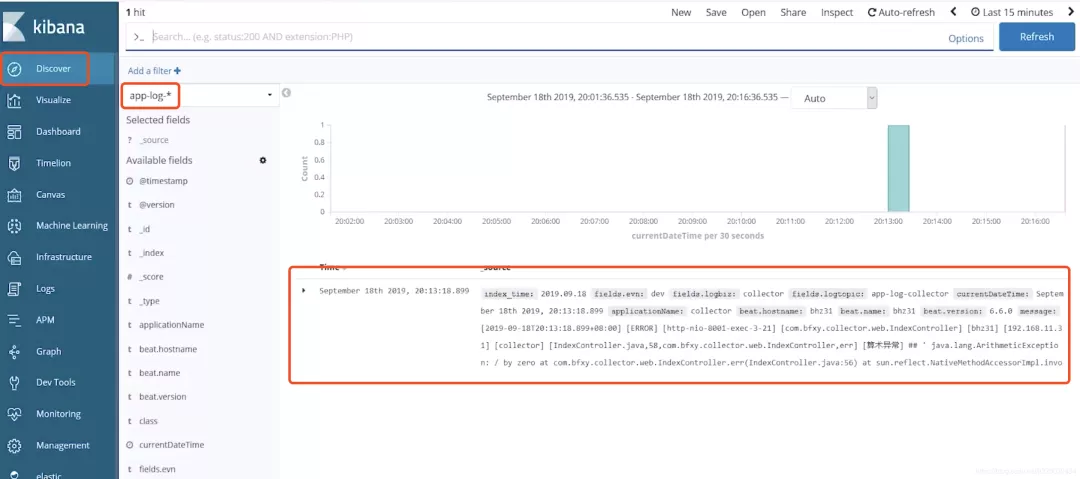
里面展示了日志的全量信息
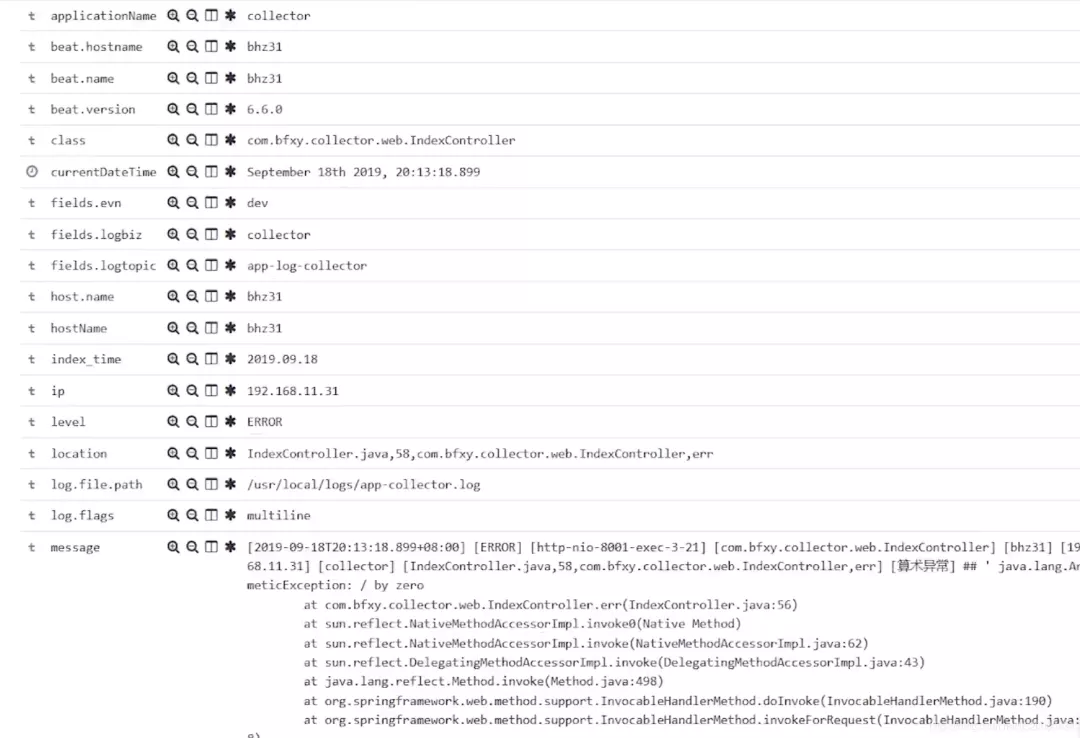
到这里,我们完整的日志收集及可视化就搭建完成了!