前言
现在一提到Redis的第一反应就是快、单线程,但是Redis真的快吗?真的是单线程吗?
你有没有深入了解一下Redis,看看它的底层有哪些”慢动作”呢?
为什么 Redis 这么火?
Redis作为一个内存数据库,它接收一个key到读取数据几乎是微妙级别,一个字快诠释了它火的原因。另一方面就归功于它的数据结构了,你知道Redis有哪些数据结构吗?
很多人可能会说不就是String(字符串)、List(列表)、Hash(哈希)、Set(集合)和 Sorted Set(有序集合)这五种吗?我想大家可能有一种误区,我说的是底层数据结构,而你说仅仅是数据的保存形式而已。
那么Redis底层有哪几种数据结构呢?和几种数据保存形式的关系又是什么呢?别着急,先通过一张图了解下,如下图:
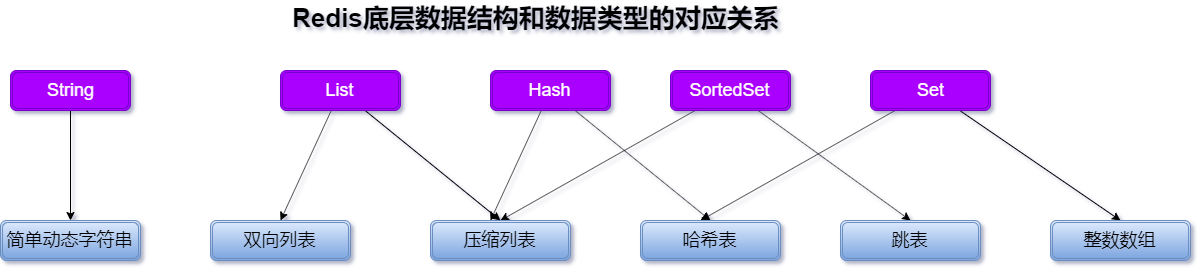
通过上图可以知道只有String对应的是一种数据结构,其他的数据类型对应的都是两种数据结构,我们通常将这四种数据类型称为集合类型,它们的特点是一个键对应了一个集合的数据。
既然数据本身是通过数据结构保存的,那么键和值是什么保存形式呢?
键和值的保存形式?
为了实现键和值的快速访问,Redis使用的是哈希表来存放键,使用哈希桶存放值。
一个
哈希表其实就是一个数组,数组的每个元素称之为哈希桶。
所以,一个哈希表是由多个哈希桶组成,每个哈希桶中保存了键值对数据。
哈希桶中保存的并不是值,而是指向值的指针。
这也解释了为什么哈希桶能够保存集合类型的数据了,也就是说不管是String还是集合类型,哈希桶保存的都是指向具体的值的指针,具体的结构如下图:

从上图可以看出,每个entry中保存的是*key和*value分别指向了键和值,这样即使保存的值是集合类型也能通过指针 *value找到。
键是保存在哈希表中,哈希表的时间复杂度是
O(1),也就是无论多少个键,总能通过一次计算就找到对应的键。
但是问题来了,当你往Redis中写入大量的数据就有可能发现操作变慢了,这就是一个典型的问题:哈希冲突。
为什么哈希表操作变慢了?
既然底层用了哈希表,则哈希冲突是不可避免的,那什么是哈希冲突呢?
Redis中的哈希冲突则是两个或者多个key通过计算对应关系,正好落在了同一个哈希桶中。
这样则导致了不同的key查找到的值是相同的,但是这种问题在Redis中显然是不存在的,那么Redis用了什么方法解决了哈希冲突呢?
Redis底层使用了链式哈希的方式解决了哈希冲突,即是同一个哈希桶中的多个元素用一个链表保存,他们之间用指针*next相连。
此时的哈希表和链式哈希的结构如下图:

从上图可以看到,entry1、entry3、entry3都保存在哈希桶 1 中,导致了哈希冲突。但是此时的entry1中的*next指针指向了entry2,同样entry2中的*next指针指向了entry3。这样下来即使哈希桶中有很多个元素,也能通过这样的方式连接起来,称作哈希冲突链。
这里存在一个问题:链表的查询效率很低,如果哈希桶中元素很多,查找起来会很慢,显然这个对于
Redis来说是不能接受的。
Redis使用了一个很巧妙的方式:渐进式 rehash。那么什么是渐进是rehash呢?
想要理解渐进式rehash,首先需要理解下的rehash的过程。
rehash也就是增加现有的哈希桶数量,让逐渐增多的entry元素能在更多的桶之间分散保存,减少单个桶中的元素数量,从而减少单个桶中的冲突。
为了使rehash操作更高效,Redis 默认使用了两个全局哈希表:哈希表1和哈希表2。一开始,当你刚插入数据时,默认使用哈希表1,此时的哈希表2并没有被分配空间。随着数据逐步增多,Redis 开始执行rehash,这个过程分为三步:
- 给
哈希表2分配更大的空间,例如是当前哈希表1大小的两倍 - 把
哈希表1中的数据重新映射并拷贝到哈希表2中 - 释放
哈希表1的空间。
以上这个过程结束,就可以释放掉哈希表1的数据而使用哈希表2了,此时的哈希表1可以留作下次的rehash备用。
此时这里存在一个问题:
rehash整个过程的第 2 步涉及到大量的拷贝,一次性的拷贝数据肯定会造成线程阻塞,无法服务其他的请求。此时的Redis就无法快速访问数据了。
为了避免一次性拷贝数据导致线程阻塞,Redis使用了渐进式rehash。
渐进式rehash则是rehash的第 2 步拷贝数据分摊到每个请求中,Redis 仍然正常服务,只不过在处理每次请求的时候,从哈希表1中索引1的位置将所有的entry拷贝到哈希表2中,下一个请求则从索引1的下一个的位置开始。
通过渐进式 rehash 巧妙的将一次性开销分摊到各个请求处理的过程中,避免了一次性的耗时操作。
此时可能有人提出疑问了:如果没有请求,那么Redis就不会rehash了吗?
Redis底层其实还会开启一个定时任务,会定时的拷贝数据,即使没有请求,rehash也会定时的在执行。
集合的操作效率?
如果是string,找到哈希桶中的entry则能正常的进行增删改查了,但是如果是集合呢?即使通过指针找到了entry中的value,但是此时是一个集合,又是一个不同的数据结构,肯定会有不同的复杂度了。
集合的操作效率肯定是和集合底层的数据结构相关,比如使用哈希表实现的集合肯定要比使用链表实现的结合访问效率要高。
接下来就来说说集合的底层数据结构和操作复杂度。
有哪些数据结构?
本文的第一张图已经列出了集合的底层数据结构,主要有五种:整数数组、双向链表、哈希表、压缩列表和跳表。
以上这五种数据结构都是比较常见的,如果读者不是很了解具体的结构请阅读相关的书籍,我就不再赘述了。
五种数据结构按照查找时间的复杂度分类如下:
| 数据结构 | 时间复杂度 |
|---|---|
| 哈希表 | O(1) |
| 跳表 | O(logN) |
| 双向链表 | O(N) |
| 压缩链表 | O(N) |
| 整数数组 | O(N) |
不同操作的复杂度?
集合类型的操作类型很多,有读写单个集合元素的,例如 HGET、HSET,也有操作多个元素的,例如SADD,还有对整个集合进行遍历操作的,例如 SMEMBERS。这么多操作,它们的复杂度也各不相同。而复杂度的高低又是我们选择集合类型的重要依据。
下文列举了一些集合操作的复杂度,总共三点,仅供参考。
1. 单元素操作由底层数据结构决定
每一种集合类型对单元素的增删改查操作这些操作的复杂度由集合采用的数据结构决定。例如,HGET、HSET 和HDEL 是对哈希表做操作,所以它们的复杂度都是O(1);Set类型用哈希表作为底层数据结构时,它的SADD、SREM、SRANDMEMBER 复杂度也是 O(1)。
有些集合类型还支持一条命令同时对多个元素的操作,比如Hash类型的HMGET和HMSET。此时的操作复杂度则是O(N)。
2. 范围操作非常耗时,应该避免
范围操作是指集合类型中的遍历操作,可以返回集合中的所有数据或者部分数据。比如List类型的HGETALL 和Set 类型的SMEMBERS,这类操作的复杂度为O(N),比较耗时,应该避免。
不过Redis提供了Scan系列操作,比如HSCAN、SSCSCAN和ZSCAN,这类操作实现了渐进式遍历,每次只返回有限数量的数据。这样一来,相比于HGETALL、SMEMBERS 这类操作来说,就避免了一次性返回所有元素而导致的 Redis 阻塞。
3. 统计操作通常比较高效
统计操作是指对集合中的所有元素个数的记录,例如LLEN 和SCARD。这类操作复杂度只有O(1),这是因为当集合类型采用压缩列表、双向链表、整数数组这些数据结构时,这些结构中专门记录了元素的个数统计,因此可以高效地完成相关操作。
总结
Redis之所以这么快,不仅仅因为全部操作都在内存中,还有底层数据结构的支持,但是数据结构虽好,每种数据结构也有各种慢的情况,Redis结合各种数据结构的利弊,完善了整个运行机制。
